

RELATED POST
産業革命を起こす勢いで進化中のAI。慶応義塾大学WPI Bio2Q特任教授の小山尚彦(こやまたかひこ)が、いまさら聞けないAIの基礎知識から最新のコンピューティング情報まで、分かりやすく解説。

小山尚彦(こやま たかひこ)慶応義塾大学WPI Bio2Q特任教授。1999年コーネル大学において物理学博士号を取得。武田薬品工業、IBMワトソン研究所を経て現職。専門はAIとQuantum Computingのライフサイエンスへの応用。武田薬品工業ではがんや中枢薬の研究、リード最適化などを行った。2014年にIBMワトソン研究所でワトソンゲノム解析のリーダーとなる。20年に発表した新型コロナウイルスの論文が中国科学院より先に発表され話題となる。大阪府出身。
「テキストを入力するだけで、プロ級の画像、リアルな音声、映画のような動画が作れる時代が到来!」
2024年から25年にかけて、生成AIの進化は目覚ましく、特にクリエイティブ分野での活用が爆発的に広がっています。Midjourney で生成される写真のようにリアルな画像、ElevenLabsで作られる有名人そっくりの音声、Soraが描き出すハリウッド映画レベルの動画、そしてChatGPT(DALL-E)を使った手軽な画像生成—これらはもはや「未来の技術」ではなく、今すぐ誰でも使える現実のツールです。特にChatGPTユーザーなら、会話の流れでそのまま「こんな画像を作って」と依頼できる手軽さが革新的で、プロンプトエンジニアリングの知識がない初心者でも高品質な画像を生成できるようになりました。 デザイナーはコンセプトアートを瞬時に作成し、YouTuberは多言語でのナレーションを自動生成し、映像制作者は従来なら何百万円もかかる特殊効果を数分で実現しています。一方で、個人のクリエイターも、これまでプロにしかできなかった高品質なコンテンツ制作が可能になりました。しかし、数多くのツールが登場している今、「どのツールを使えばいいのか」「それぞれの特徴や得意分野は何か」といった疑問を持つ方も多いでしょう。
今回は、画像・音声・動画生成AIの代表的なツールを実際に比較し、それぞれの特徴、使いどころ、料金体系まで詳しく紹介していきます。あなたの目的に最適なツール選びの参考にしてください。
画像生成AIの最前線:
技術革新の背景拡散モデルが変えた世界
画像生成AIの爆発的普及は、22年の「拡散モデル」実用化が転換点でした。従来のGAN技術と比べて学習が安定し、「ノイズから徐々に画像を構築する」直感的なプロセスにより、テキストによる細かい制御が可能になったのです。Stable Diffusion、DALL-E、Midjourneyなど主要ツールはすべてこの技術をベースにしています。
自然言語の「視覚化」技術
「夕日に照らされた古い灯台」といった抽象的な表現を、AIが理解できる数値データに変換するCLIP技術(OpenAIが開発した「画像とテキストを同じ空間で理解する」技術)の進歩により、複雑な構図や芸術的スタイルまで対応可能になりました。最新モデルでは「ピカソ風の猫の肖像画」「1980年代のSF映画ポスター風」など、複数概念の組み合わせも正確に理解します。
学習データ戦略の違いが生む個性
各社の学習データ戦略の違いが、ツールの特色を決定しています。Midjourneyは高品質アート作品重視、Adobe Fireflyは権利クリアなStock画像のみ、Stable Diffusionは大規模Web画像活用と、それぞれ異なるアプローチを取ることで、芸術性・商用安全性・多様性といった特徴を生んでいます。
「創作の民主化」の実現
技術進歩により、従来は大手制作会社でなければ作れなかった高品質ビジュアルが個人でも制作可能になりました。同時に「プロンプトエンジニアリング」という新スキルが生まれ、写真家やデザイナーの専門用語が誰でも使えるクリエイティブツールになっています。リアルタイム生成技術により、静的な「完成品制作」から動的な「アイデア探索」へとデザインプロセス自体も変化しています。
主要な画像生成AIサービス比較
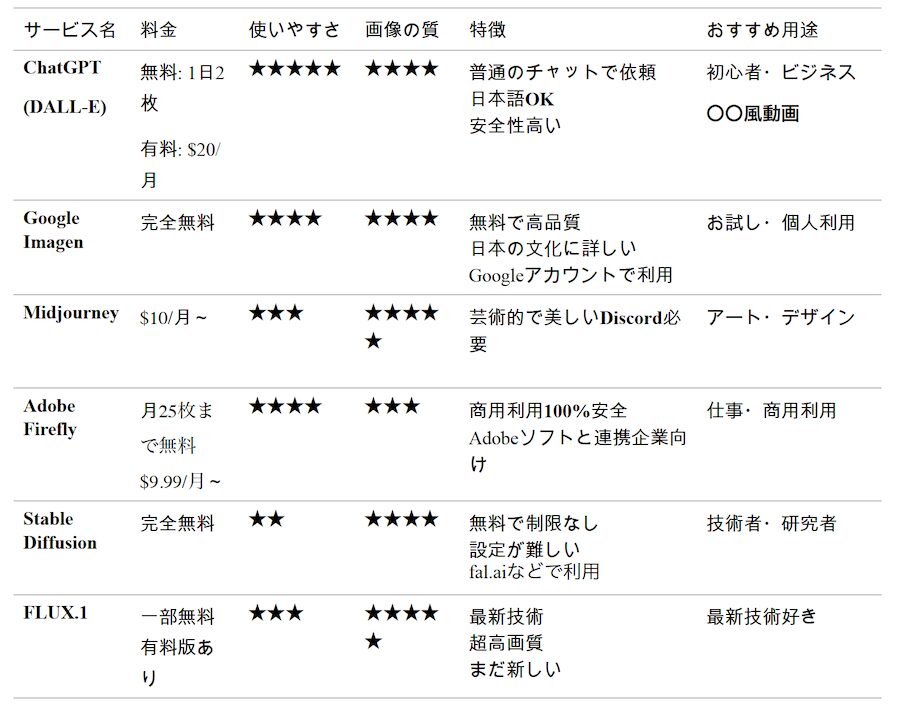
サブスクリプションが必要なMidjourneyを除く5つの画像生成AIプラットフォームでいくつか画像を作ってみました。それぞれ、得意不得意ならびに好みがあると思いますので、いくつかのプラットフォームで試してみるのが良いと思います。fal.aiがいろいろなプラットフォームにアクセスできるので便利です。

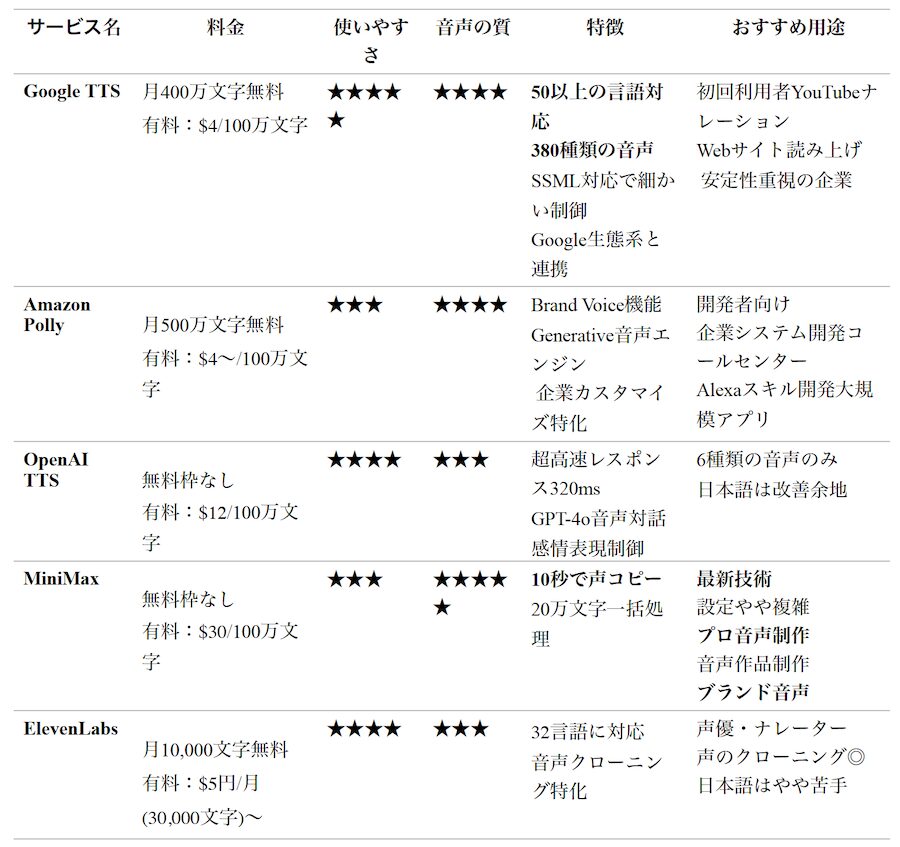
音声生成AIの最前線:
人間の声を超えた技術ニューラル音声合成の革命
音声生成AIの現在の品質は、従来のロボット的な合成音声とは別次元です。実は1980年代前半、私がパソコン少年だった中学生の頃にも音声合成は存在していました(当時、タモリさんが宣伝していた富士通のFM77を所有)。当時は専用の音声合成ボードをパソコンに挿して、「コンニチハ」「アリガトウゴザイマス」と機械的な声で話すソフトウェアがありましたが、高価で手が出ませんでした。 それから40年余り、2020年代前半のWaveNetから始まり、現在のTransformerベースのモデルに至るまで、ニューラルネットワークによる音声合成技術は人間の声と区別がつかないレベルに到達しています。
わずか数秒の音声からクローン生成
最新の音声生成AIの驚異的な点は、わずか数秒から数分の音声サンプルがあれば、その人の声を完全に再現できることです。声の特徴、話し方のクセ、感情の込め方まで学習し、全く新しい文章を自然に読み上げることができます。これは「ゼロショット音声クローニング」と呼ばれる技術によるものです。
ただし、日本語の読みはまだ難しいところがあるようで、漢字の読み方や固有名詞で小学生のように読み間違いをすることもあります。また、イントネーションがおかしいところもあって、思わずつっこみたくなることも。特に同音異義語や文脈に依存する読み分けは、今後の改善課題となっています。
多言語対応とリアルタイム処理
現在の音声生成AIは、一つの声モデルで複数言語に対応できます。日本語で学習した声で英語を話させることも可能で、アクセントや発音の特徴も自然に再現されます。さらに、リアルタイム処理技術により、入力と同時に音声が生成される「会話型AI」の実現も近づいています。
感情制御と表現力の向上
単純な読み上げから、感情豊かな表現まで制御できるようになったのも大きな進歩です。「悲しそうに」「興奮して」「ささやくように」といった指示により、同じテキストでも全く異なる印象の音声を生成できます。ポッドキャスト、オーディオブック、ゲームのキャラクターボイスなど、エンターテインメント分野での活用が急速に広がっています。
業界への影響と新たな可能性
音声生成AIは、ナレーション業界、語学教育、アクセシビリティー向上など幅広い分野に影響を与えています。覚えたい単語で物語を作り、それを音声生成AIでmp3にして持ち歩くことだって可能です。筆者も子どもの英語学習用にSATレベルの語彙を使った話を作ったりしています。(https://www.youtube.com/watch?v=F3lX8j2IFHQ)
多言語でのコンテンツ展開、視覚障害者向けの読み上げサービス、個人のYouTubeチャンネルでのプロ級ナレーション制作など、従来は高コストだった音声コンテンツ制作が身近になりました。
一方で、ディープフェイク音声による悪用リスクも指摘されており、各社は本人確認機能や透かし技術の開発も進めています。
以下のリンクから声のサンプルが聞けます:
Google TTS(Text to Speech)
https://cloud.google.com/text-to-speech/docs/voices?hl=ja
Open AI:
https://www.openai.fm
MiniMax
https://www.minimax.io/audio/voices
ElevenLab
https://elevenlabs.io/ja/text-to-speech/japanese
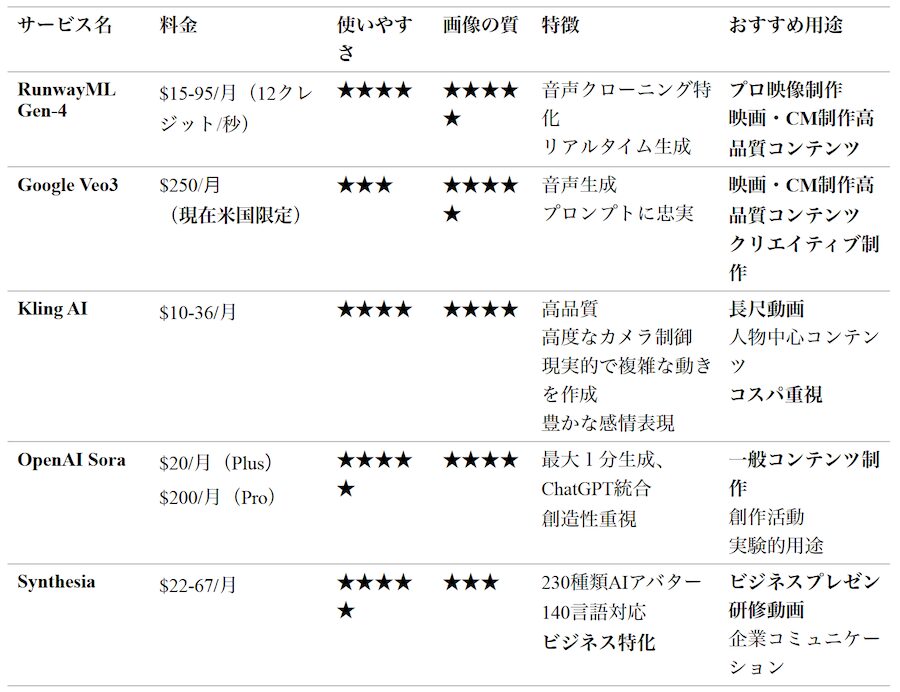
動画生成AIの最前線:
映像制作の新時代静止画から動く映像への大飛躍
動画生成AIは、画像生成AIよりもはるかに複雑な技術的課題を抱えています。単に美しい画像を作るだけでなく、時間軸での一貫性、物理法則に従った動き、カメラワークの自然さなど、多くの要素を同時に制御する必要があるからです。
それでも2024年のOpenAI「Sora」登場により、テキストプロンプトだけで映画レベルの映像を生成できる時代が到来しました。Soraのデモ動画として公開された「女性が東京の街を歩く」映像は、世界中に衝撃を与えました(https://openai.com/ja-JP/index/sora/?video=913331489)。リアルな人物の表情、自然な歩き方、東京の街並みの細部まで、60秒という長尺にわたって一貫して美しく生成された映像は、まさに革命的でした。
物理法則とカメラワークの理解
最新の動画生成AIが驚異的なのは、物理法則を理解していることです。水が流れる様子、煙が立ち上る動き、布が風でなびく表現など、現実世界の物理現象を自然に再現できます。さらに、映画的なカメラワークなども指定できるため、プロの映像制作者が作ったような作品を生成可能です。
まだ残る「不気味の谷」現象
ただし、動画生成AIにはまだ課題も多く残されています。初期の動画生成AIで話題になったのが、Will Smithがスパゲッティを食べる動画でした(https://www.youtube.com/watch?v=XQr4Xklqzw8)。
現在でも、人物の手指の動きが不自然になったり、背景のオブジェクトが突然消えたり現れたりする現象がしばしば発生します。また、画像生成AIと比べて文字の表示が苦手で、看板や本の文字が判読不能な文字化けのようになってしまうことも多々あります。長時間の動画では一貫性を保つのが困難で、キャラクターの服装や髪型が途中で変わってしまうこともあります。これらは「時間的一貫性」の問題として、各社が改善に取り組んでいる分野です。
リアルタイム生成への挑戦
現在の動画生成AIは、数分から数時間の処理時間を要しますが、リアルタイム生成への挑戦も始まっています。ゲームやライブ配信での活用を見据え、数秒で短い動画クリップを生成する技術の開発が進められています。
映像制作業界への衝撃
従来、映画やCMの制作には大規模なスタッフと高額な予算が必要でした。しかし動画生成AIにより、個人でもハリウッド級の特殊効果を含む映像を制作できるようになりつつあります。広告業界、教育コンテンツ制作、個人のYouTubeチャンネルまで、幅広い分野で活用が始まっており、映像制作の民主化が急速に進んでいます。
一方で、俳優や映像制作者の権利保護、フェイク動画の悪用防止など、新たな課題も浮上しており、技術の進歩と社会的責任のバランスが重要な議論となっています。
画像、音声、動画の生成AIは、わずか数年で「未来の技術」から「日常のツール」へと変貌を遂げました。1980年代の高価な専用ボードが必要だった機械的な音声合成から、今では誰もがスマートフォンで映画レベルの動画を生成できる時代になったのです。
画像生成では拡散モデルとCLIPの組み合わせにより、テキストから芸術的な画像を瞬時に生成できるようになりました。音声生成では、わずか数秒のサンプルから感情豊かな音声クローンを作成可能になり、動画生成では物理法則を理解して映画的なカメラワークを含む長尺動画まで生成できるようになっています。
もちろん課題も残されています。音声では日本語の読み間違いや不自然なイントネーション、動画では時間的一貫性の問題や文字表示の苦手さ、そして共通して手指の動きや細部の不自然さなどがあります。
それでも、これらの技術は個人クリエイターからプロの制作現場まで、創作活動を根本から変えつつあります。専門知識がなくても高品質なコンテンツを制作できる「創作の民主化」が実現し、新しいビジネスモデルや表現手法が次々と生まれています。
次回予告:AIの進化
第4回では、最近よく耳にするAIエージェントについて解説します。お楽しみに。
*料金などは変更になることがありますので、事前にご確認ください。
筆者がSORAで作った動画:
Koyama Lab
Dancing Bacteria
Fractal


RECOMMENDED
-

客室乗務員が教える「本当に快適な座席」とは? プロが選ぶベストシートの理由
-

NYの「1日の生活費」が桁違い、普通に過ごして7万円…ローカル住人が検証
-

ベテラン客室乗務員が教える「機内での迷惑行為」、食事サービス中のヘッドホンにも注意?
-

パスポートは必ず手元に、飛行機の旅で「意外と多い落とし穴」をチェック
-

日本帰省マストバイ!NY在住者が選んだ「食品土産まとめ」、ご当地&調味料が人気
-

機内配布のブランケットは不衛生かも…キレイなものとの「見分け方」は? 客室乗務員はマイ毛布持参をおすすめ
-

白づくめの4000人がNYに集結、世界を席巻する「謎のピクニック」を知ってる?
-

長距離フライト、いつトイレに行くのがベスト? 客室乗務員がすすめる最適なタイミング
-

機内Wi-Fiが最も速い航空会社はどこ? 1位は「ハワイアン航空」、JALとANAは?
-

「安い日本」はもう終わり? 外国人観光客に迫る値上げラッシュ、テーマパークや富士山まで











